
検索結果
このウィキでページ「辞書検索 アルゴリズム」は見つかりませんでした。以下の検索結果も参照してください。
- 検索(文書検索、文字列探索)、画像データの検索(画像検索)、音声データの検索(音声検索)など、大規模かつマルチメディアの情報に関する検索技術が発展した。さらにデータベースの発展とインターネットの普及に伴い、分散保管されているデータに対する検索…12キロバイト (1,571 語) - 2024年3月28日 (木) 13:23
 アルゴリズムであり、これによって検索文字列に最も適したウェブページを上位に表示できる。Google以前の主な検索エンジンはキーワードに基づいて検索結果の順位付けをしていた。それは、検索文字列がそのページ内に出現する頻度を順位付けの基本とし、それによって検索…45キロバイト (5,638 語) - 2024年4月29日 (月) 11:51
アルゴリズムであり、これによって検索文字列に最も適したウェブページを上位に表示できる。Google以前の主な検索エンジンはキーワードに基づいて検索結果の順位付けをしていた。それは、検索文字列がそのページ内に出現する頻度を順位付けの基本とし、それによって検索…45キロバイト (5,638 語) - 2024年4月29日 (月) 11:51- 形態素解析によるわかち書きは採用せず。 詳細なアルゴリズムは不明だが、文字種により単語を分割し、インデックスに登録していくタイプと思われる。 ひらがなは事前に辞書登録されたもの以外は検索できない。 アルゴリズムが単純な分、インデクシングが極めて高速。 コンセプトサーチ(ジャストシステム) 自然言語による検索が可能。…24キロバイト (3,156 語) - 2023年7月16日 (日) 14:30
- ChemSpider (検索の節)辞書が作られた。 いくつかの検索機能が提供されている。 standard searchでは、クエリとして系統名、商品名、別名、登録番号を用いることができる。 advanced searchでは、分子式、分子量、CAS番号、納入業者等の情報を用いて、化学構造、基礎構造による相互検索ができる。…6キロバイト (750 語) - 2023年11月10日 (金) 13:26
- 文字列探索 (文字列検索アルゴリズムからのリダイレクト)欧米語のような、空白文字列で区切られている言語のテキストに関しては、効率のよいアルゴリズムが知られている。ところが日本語のように「どこからどこまでに対して辞書引きをするか」が不明確な場合、「あるバイト列に対し、不定長のバイト列に対して検索を行う」という作業が必要となる。…4キロバイト (505 語) - 2023年8月19日 (土) 16:39
- 7-Zip実装には、ハッシュチェイン、二分木、基数木を辞書検索アルゴリズムの基礎とする、複数の変種がある。 LZMAの伸長専用コードはC言語で記述されていて、通常5kB前後にコンパイルされる。また、伸長に必要なRAMの量は、主に圧縮時のスライド窓の大きさによって決定する。小さいコードサイズと、辞書…10キロバイト (1,349 語) - 2023年7月15日 (土) 18:07
- フォード・ファルカーソンのアルゴリズム(英: Ford-Fulkerson algorithm)とは、フローネットワークにおける最大フローを求めるアルゴリズムである。レスター・フォード Jr.(英語版、ドイツ語版、フランス語版、ロシア語版) と デルバート・ファルカーソン(英語版、ドイツ語版、スペイン語版、フランス語版)…8キロバイト (1,117 語) - 2018年4月10日 (火) 17:31
 た。コンピュータが普及し、統一的な管理番号が求められたことが背景にある。これは翌年にイギリス国内で利用され始めた。1967年、国際規格ISBNのアルゴリズムが考案された。ISBNは国際標準化機構 (ISO) で1970年に採用された (ISO 2108)。 なお、出版物(本)に関する国際標準化機構の…19キロバイト (2,089 語) - 2023年9月27日 (水) 04:37
た。コンピュータが普及し、統一的な管理番号が求められたことが背景にある。これは翌年にイギリス国内で利用され始めた。1967年、国際規格ISBNのアルゴリズムが考案された。ISBNは国際標準化機構 (ISO) で1970年に採用された (ISO 2108)。 なお、出版物(本)に関する国際標準化機構の…19キロバイト (2,089 語) - 2023年9月27日 (水) 04:37- JBIG2 (カテゴリ 可逆圧縮アルゴリズム)般的には、MQコーダと呼ばれるコンテキスト依存の算術符号アルゴリズムを使用して圧縮される。テキスト領域は、次のように圧縮される。領域の前景ピクセルは、シンボルにグループ化される。次に、一般的には、コンテキスト依存算術符号を使用してシンボルの辞書が作成されて符号化され、領域は、どのシンボルがどこに現れ…14キロバイト (1,791 語) - 2022年7月23日 (土) 22:15
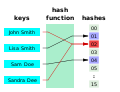 ハッシュ関数 (カテゴリ 検索アルゴリズム)てハッシュ関数を適用して上述してきたような技法で同じ部分や類似の部分を探す。 ラビン-カープ文字列検索アルゴリズムは比較的高速な文字列検索アルゴリズムで、平均でO(n)の時間で動作する。このアルゴリズムは文字列の比較にハッシュ関数を使っている。 この原理は、コンピュータグラフィックスや計算幾何学を代…32キロバイト (4,746 語) - 2023年8月3日 (木) 17:44
ハッシュ関数 (カテゴリ 検索アルゴリズム)てハッシュ関数を適用して上述してきたような技法で同じ部分や類似の部分を探す。 ラビン-カープ文字列検索アルゴリズムは比較的高速な文字列検索アルゴリズムで、平均でO(n)の時間で動作する。このアルゴリズムは文字列の比較にハッシュ関数を使っている。 この原理は、コンピュータグラフィックスや計算幾何学を代…32キロバイト (4,746 語) - 2023年8月3日 (木) 17:44- 接尾辞配列 (カテゴリ 検索アルゴリズム)接尾辞配列を使えば検索対象文字列の出現位置を高速に検索することができる。接尾辞配列においては、文字列が出現する位置を求めることはつまり、その文字列で始まっている接尾辞を求めることと同じである。接尾辞配列は辞書順にソートされているので、検索対象となる文字列の検索には、高速な二分探索アルゴリズムが利用できる。…8キロバイト (1,085 語) - 2021年8月19日 (木) 15:58
- エイホ–コラシック法 (カテゴリ 検索アルゴリズム)algorithm)とは、1975年にアルフレッド・エイホと Margaret J. Corasick が発見した文字列探索アルゴリズムである。 エイホ–コラシック法は、入力テキストについて有限の文字列群(辞書)の各要素を探す辞書式マッチングアルゴリズムの一種である。全パターンのマッチングを一斉に探索するため、そのアルゴリズム…6キロバイト (637 語) - 2022年8月30日 (火) 06:57
 チェス (マテリアルアドバンテージの節)「氷上のチェス」といわれる。 グレート・ゲーム - 情報戦をチェスに例えた表現。 ウィキペディアの姉妹プロジェクトで 「チェス」に関する情報が検索できます。 ウィクショナリーの辞書項目 コモンズのメディア ウィキクォートの引用句集 ウィキブックスの教科書や解説書 チェス(西洋将棋)の手ほどき : 附記・ドミノの遊び方…52キロバイト (6,743 語) - 2024年3月15日 (金) 03:42
チェス (マテリアルアドバンテージの節)「氷上のチェス」といわれる。 グレート・ゲーム - 情報戦をチェスに例えた表現。 ウィキペディアの姉妹プロジェクトで 「チェス」に関する情報が検索できます。 ウィクショナリーの辞書項目 コモンズのメディア ウィキクォートの引用句集 ウィキブックスの教科書や解説書 チェス(西洋将棋)の手ほどき : 附記・ドミノの遊び方…52キロバイト (6,743 語) - 2024年3月15日 (金) 03:42 迷路 (トレモー・アルゴリズムの節)ウィキメディア・コモンズには、迷路に関連するメディアがあります。 ウィクショナリーに関連の辞書項目があります。 迷路 迷宮 ダンジョン 脱出ゲーム マッピー 迷路コンピュータゲームの一覧 迷路生成アルゴリズム(英語版) コントロール (オリエンテーリング)(英語版) - チェックポイント ポルセンナの迷宮(イタリア語版)…18キロバイト (2,622 語) - 2024年2月5日 (月) 11:25
迷路 (トレモー・アルゴリズムの節)ウィキメディア・コモンズには、迷路に関連するメディアがあります。 ウィクショナリーに関連の辞書項目があります。 迷路 迷宮 ダンジョン 脱出ゲーム マッピー 迷路コンピュータゲームの一覧 迷路生成アルゴリズム(英語版) コントロール (オリエンテーリング)(英語版) - チェックポイント ポルセンナの迷宮(イタリア語版)…18キロバイト (2,622 語) - 2024年2月5日 (月) 11:25- QuickLZ や Snappy 相当、--fast=3 は LZO 相当、--fast=4 は LZ4 相当である。 Zstandardは大きな検索窓の辞書式圧縮アルゴリズム (LZ77) とエントロピー符号化を併用しており、エントロピー符号化ステージで有限状態エントロピー(FSE)のtANS(英語版)…15キロバイト (1,427 語) - 2024年5月4日 (土) 05:13
 zlib/deflate(いわゆるgzip形式。ZIPではないので注意)アルゴリズムで圧縮するもの。;PDF 1.2より実装 LZWDecode LZWアルゴリズムで圧縮するもの。 RunLengthDecode ランレングスアルゴリズムによるシンプルな圧縮 DCTDecode JPEGに採用された 非可逆圧縮…91キロバイト (11,344 語) - 2024年5月18日 (土) 13:58
zlib/deflate(いわゆるgzip形式。ZIPではないので注意)アルゴリズムで圧縮するもの。;PDF 1.2より実装 LZWDecode LZWアルゴリズムで圧縮するもの。 RunLengthDecode ランレングスアルゴリズムによるシンプルな圧縮 DCTDecode JPEGに採用された 非可逆圧縮…91キロバイト (11,344 語) - 2024年5月18日 (土) 13:58 トライ (データ構造) (辞書表現の節)対応する記号(文字)はその順序が暗黙のうちに決定される(辞書順など)。 キーは必ずしもノードに格納される必要はない。右図はトライ木の概念を示したもので実装は一般に異なる。 トライ木のキーは必ずしも文字列である必要はない。トライ木のアルゴリズムを文字列以外の任意のデータ構造に適用することは容易である。…19キロバイト (2,679 語) - 2023年3月2日 (木) 13:01
トライ (データ構造) (辞書表現の節)対応する記号(文字)はその順序が暗黙のうちに決定される(辞書順など)。 キーは必ずしもノードに格納される必要はない。右図はトライ木の概念を示したもので実装は一般に異なる。 トライ木のキーは必ずしも文字列である必要はない。トライ木のアルゴリズムを文字列以外の任意のデータ構造に適用することは容易である。…19キロバイト (2,679 語) - 2023年3月2日 (木) 13:01- ラムの段階的詳細化法の知見から、プログラムを構成するアルゴリズムとそのアルゴリズムで用いられるデータ構造は密接に関連しており、アルゴリズムをある程度詳細化してからでないと多くの場合そのデータ構造は決定できないことを指摘した。 さらに、アルゴリズムに関連するデータ構造を決定するためには、まず必要なデ…10キロバイト (1,206 語) - 2023年9月27日 (水) 18:27
 圧縮データには、画像の分類、検索、または参照に使用できる画像に関する情報が含まれている場合があります。このような情報には、色とテクスチャの統計、小さなプレビュー画像、作者または著作権情報が含まれる。 処理能力 圧縮アルゴリズムは、エンコードとデコードに異なる量の処理能力を必要とする。 一部の高圧縮アルゴリズムは、高い処理能力を必要とする。…17キロバイト (2,089 語) - 2023年8月27日 (日) 23:49
圧縮データには、画像の分類、検索、または参照に使用できる画像に関する情報が含まれている場合があります。このような情報には、色とテクスチャの統計、小さなプレビュー画像、作者または著作権情報が含まれる。 処理能力 圧縮アルゴリズムは、エンコードとデコードに異なる量の処理能力を必要とする。 一部の高圧縮アルゴリズムは、高い処理能力を必要とする。…17キロバイト (2,089 語) - 2023年8月27日 (日) 23:49- 特に固有名詞の語彙は、他の日本語入力システムと比べ極めて多い。 予測変換に用いる辞書は、Google 検索の検索ワードからなるビッグデータを使用し生成するため、検索されやすい流行言葉などの予測精度は、インターネット上で大きな話題となった。 他方、検索ワードが予測変換に影響するため、一般的な語彙と同音な流行言葉が予測変換を埋めてしまう。…29キロバイト (3,638 語) - 2024年4月4日 (木) 06:48








- は、単に値の有無を確認するだけの目的で使用します。 バイナリ検索アルゴリズムを使用する際の前提条件は、検索対象の範囲がソート済みであることです。範囲がソートされていない場合、結果は不確定となります。 バイナリ検索は、以下のような場面で利用できます。 辞書やデータベースから特定のキーを検索する ソートされた大規模データから特定の値を探す